
LDA主题模型第一步:数据采集
软件介绍
数据采集其实就是通过爬取网页中有用的一些信息的过程,也就是网络爬虫,常用的软件主要是python,R语言也可以,但是对初学者来说,尤其是非计算机专业的同学来说,会有一些困难,那有没有现成的傻瓜式工具呢,这就要提到我么今天所讲的工具: 八爪鱼采集器。这个工具是把爬虫技术封装到软件中了,用起来相对方便一些,基本上学了就能会。但是其中还有一些注意事项,今天给大家介绍一下,话不多说,开始上手。
具体步骤
(1)下载八爪鱼采集器
| 下载地址可以百度搜索一下,或者直接 点击此处 就可以进入下载页面了。这个是Windows版本的,mac版本链接底部也能看到,下载对应版本即可。下载后自行注册一个账号,然后就可以开工啦,不用开会员,学生的话,免费版暂时够用了。 |
(2)打开有问必答网
| 我们今天教程的举例主要使用的是 有问必答网 ,大家可以百度或者直接点击红色字体进入。文本挖掘的主要信息是:HIV患者的健康信息需求。因此请大家打开HIV相应的版块,如下图。 |
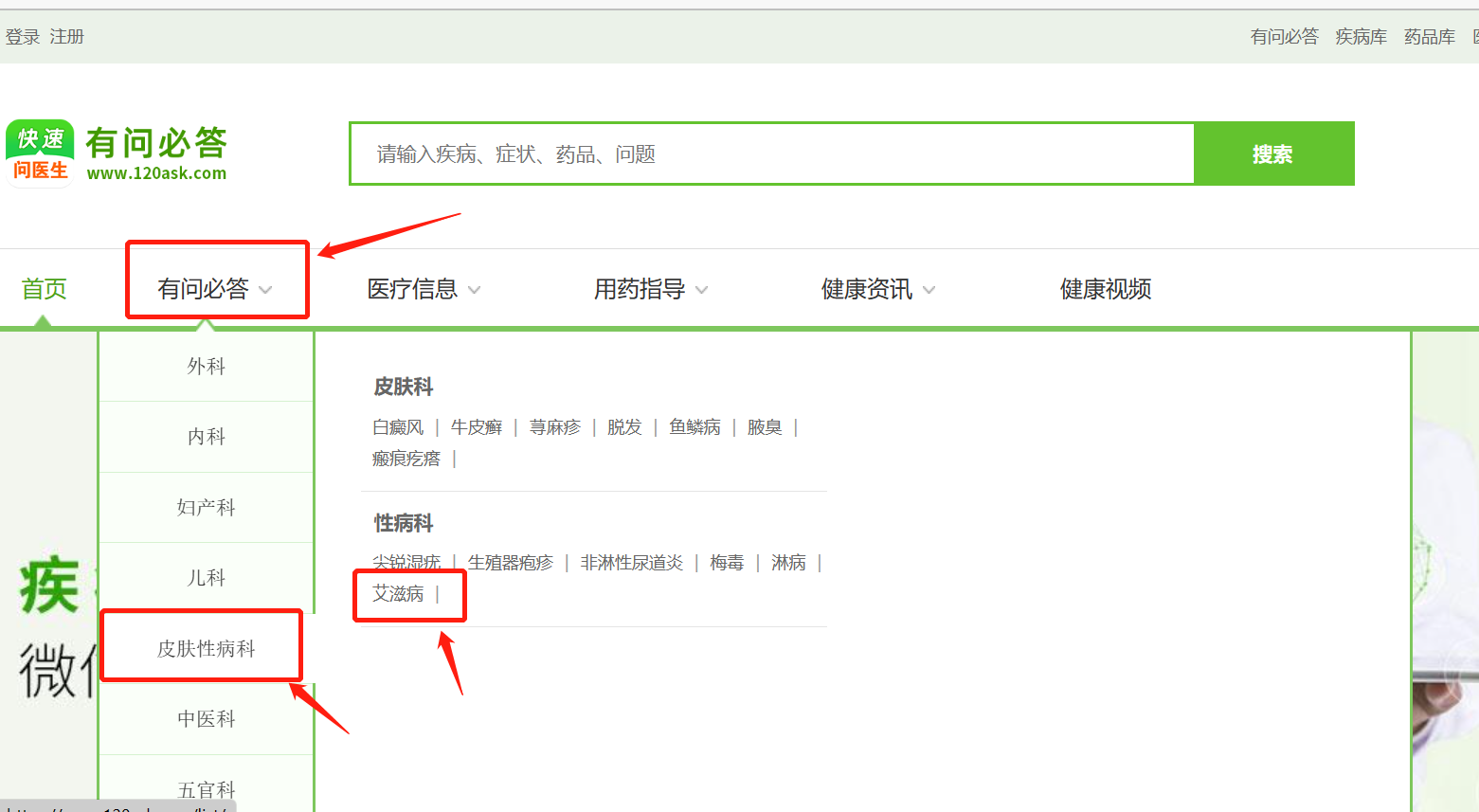
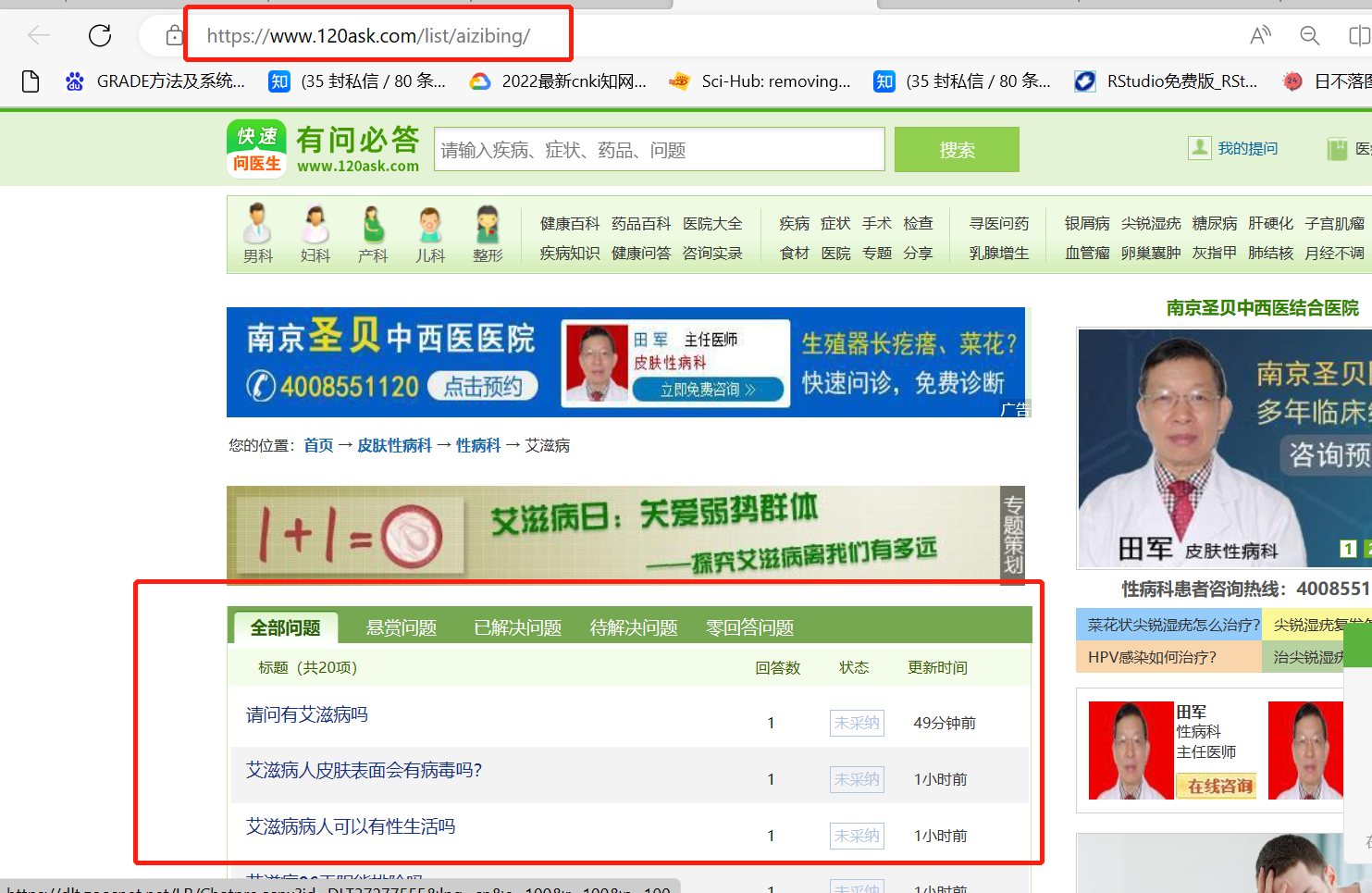
| 进入之后大家可以看到许多患者的提问,这个就是我们需要抓取的内容。大家把这个网页的网址复制下载,然后打开八爪鱼软件。 |
(3)新建采集
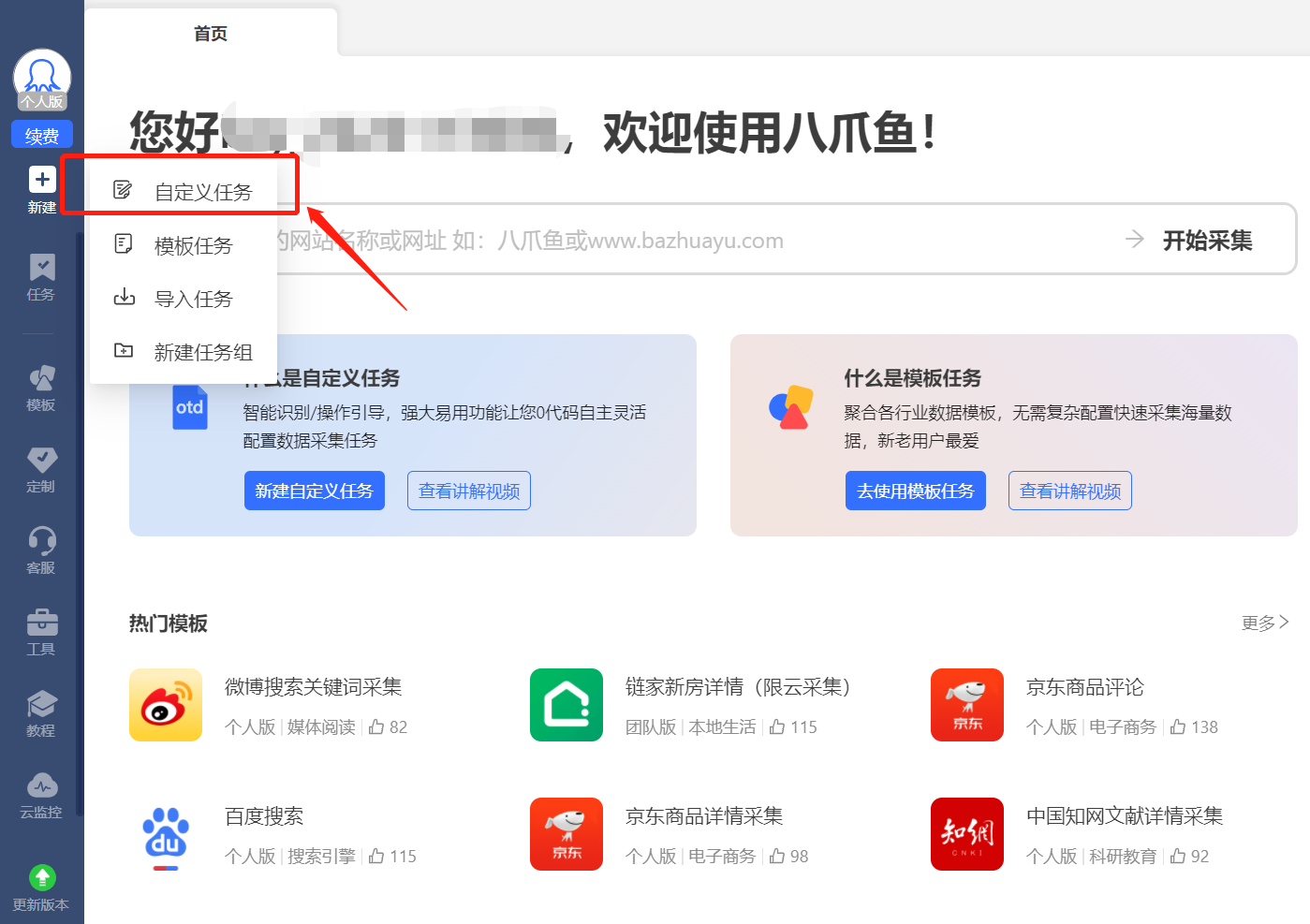
| 大家点击 新建任务 ,任务组命名为有问必答网。 |
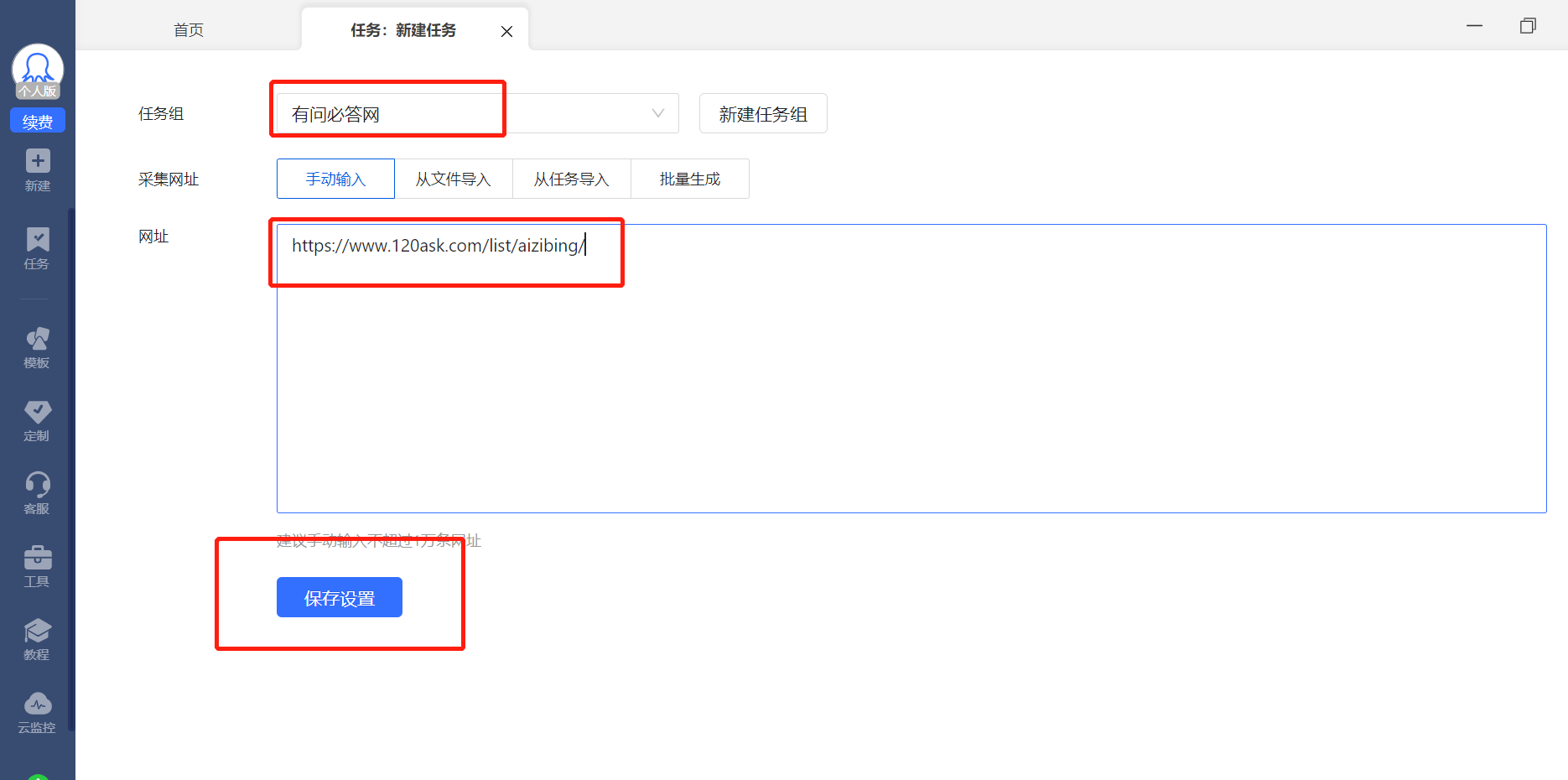
| 将链接复制到网址一栏,然后点击 保存设置 ,会跳转到新界面。 |
| 之后点击 自动识别网页 ,然后就不用管了,等待网页自动识别完成。 |
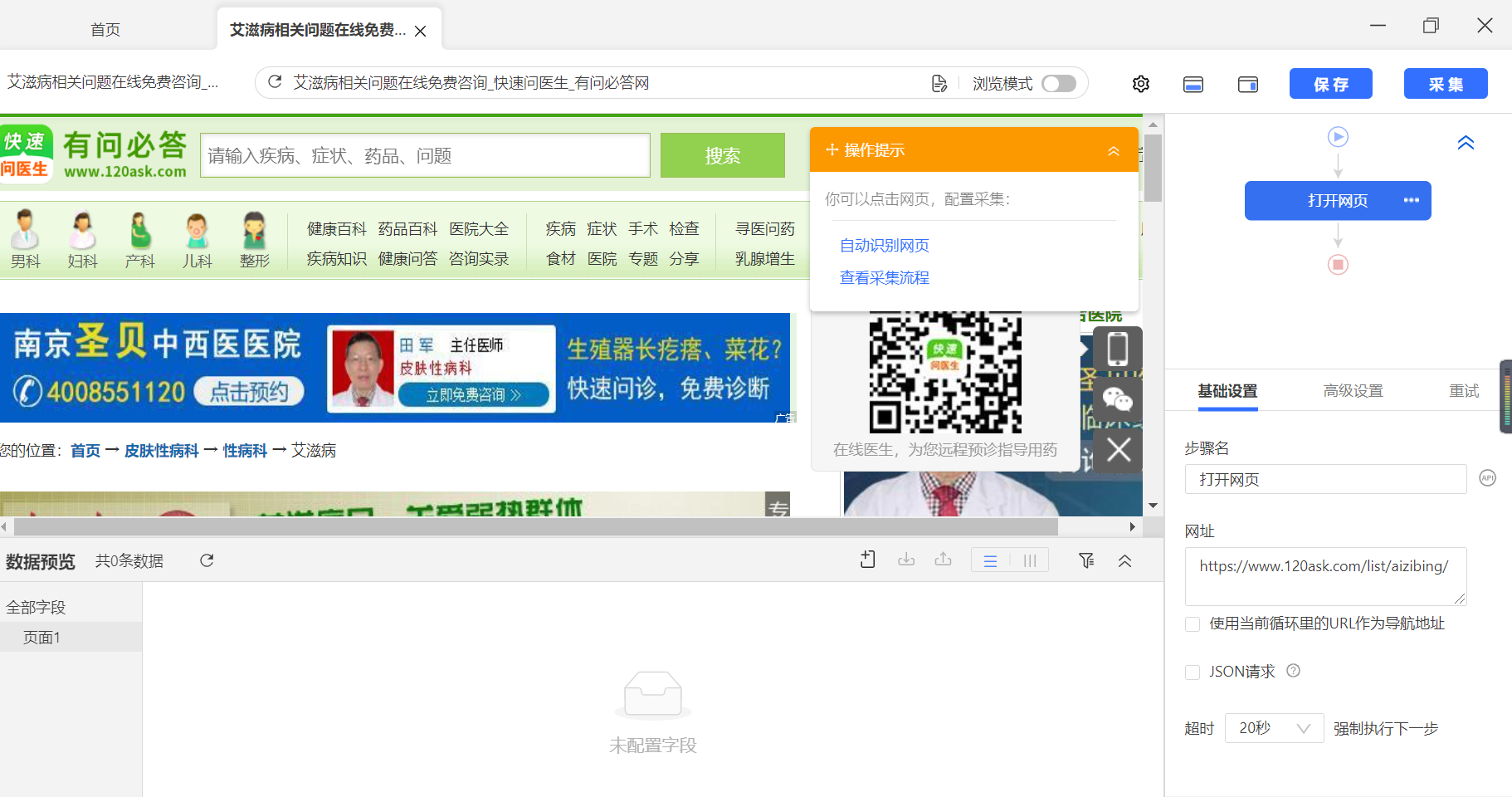
| 然后点击 生成采集设置 。下一步很关键,点击 设置加载更多按钮 ,然后页面下拉知道看到如图下方的“下一页”按钮,点击之后,右上角的操作提示中也会出现“下一页”。然后还可以设置加载的页数,设置为200就是说抓取前200页的数据。当然这个根据自己要求设置,可以抓取前300页 不过大家刚开始学习的话,我建议大家只采集前50页就行,先熟悉流程后再考虑采集更多页面,因为采集页面太多,时间也会很长 。之后点击“确定”。然后点击右上角保存。这样下次可以直接用这个模板进行采集,就不用设置啦。 |
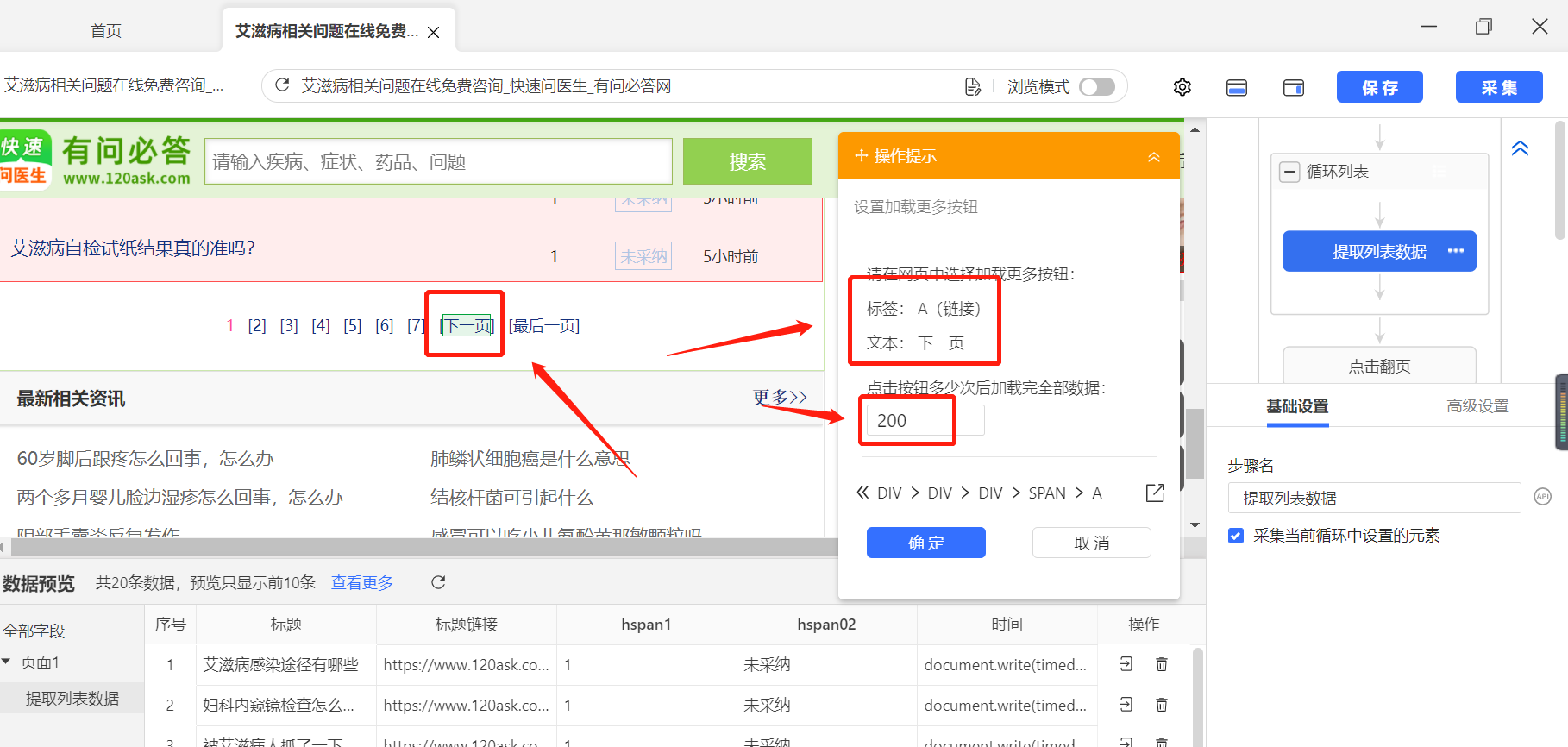
(4)开始采集
大家上一步设置好了以后,可以点击右上方进行采集。选择 本地采集→普通模式 即可开始采集啦。然后点击右上角显示网页可以看到具体的采集过程。大家如果初次尝试的话,可以采集一些数据之后就点击停止,先熟悉流程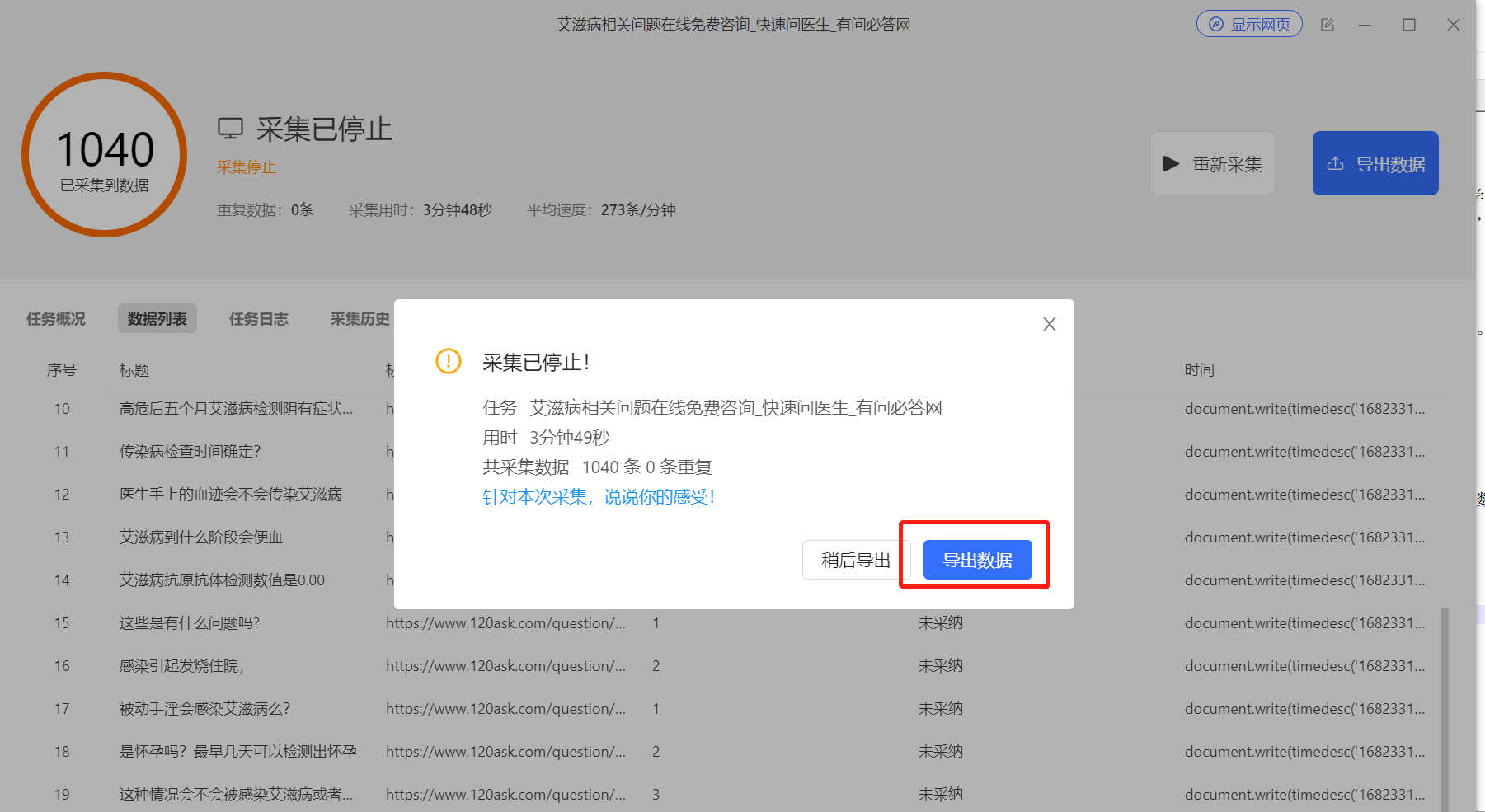
(5)采集结束
软件会根据前期设置的采集页数进行采集,采集结束后会提示采集完成,之后可以将采集的数据导出成CSV格式(我比较喜欢这种格式,用起来很方便)。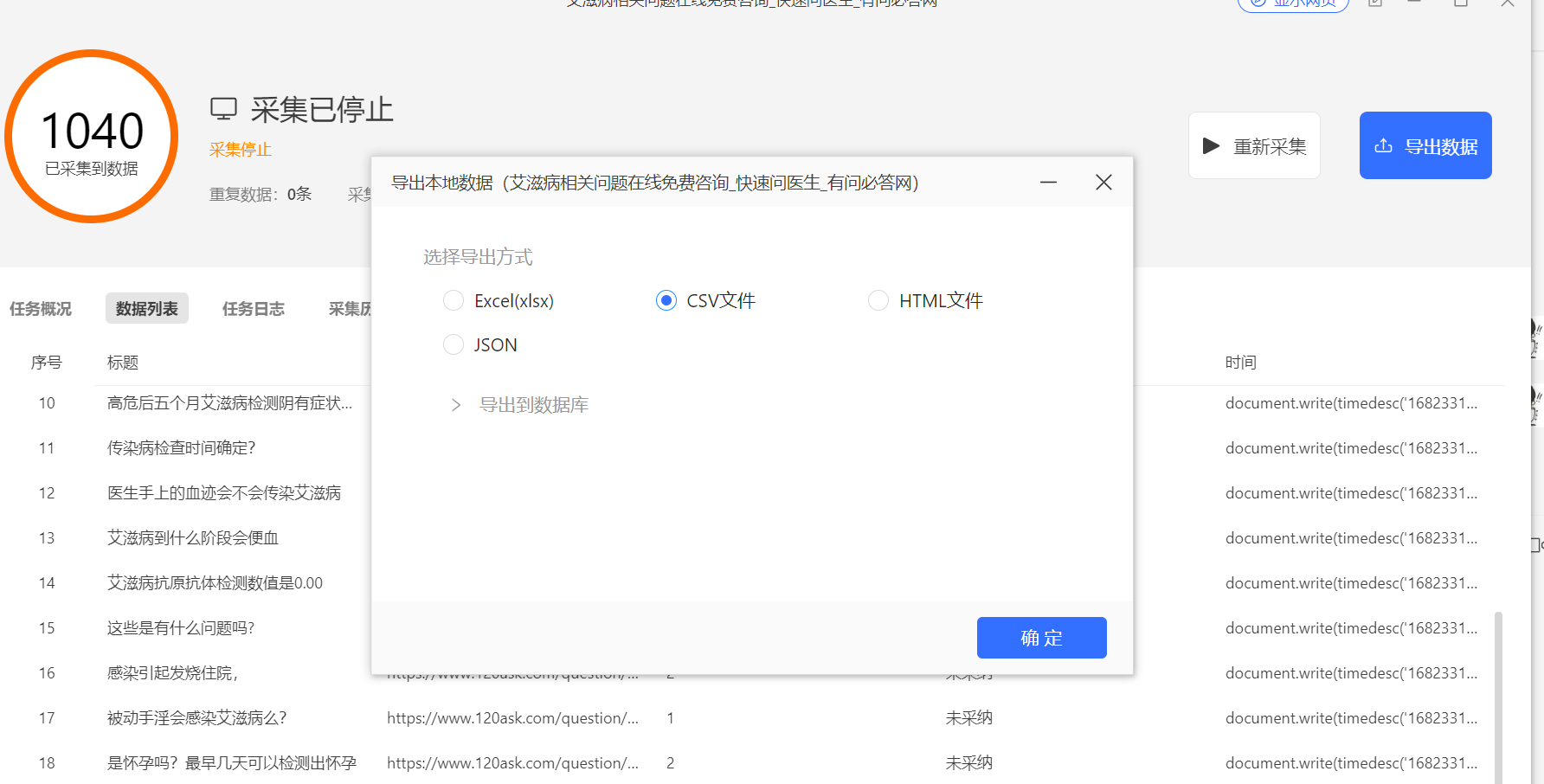
大家可以将数据导出到自己设置的位置。打开文件,就可以看到采集的数据啦,如下图所示:标题栏就是我们需要的信息。事实上我们可以采集到更多的信息,比如提问者的年龄、省份、性别等等,这些数据在二级页面里边,但是我们这一次主要是先熟悉流程,采集更多信息设置也会更复杂一些,为了不增加大家负担,这里先不过多介绍,后期出一个进阶版的采集攻略。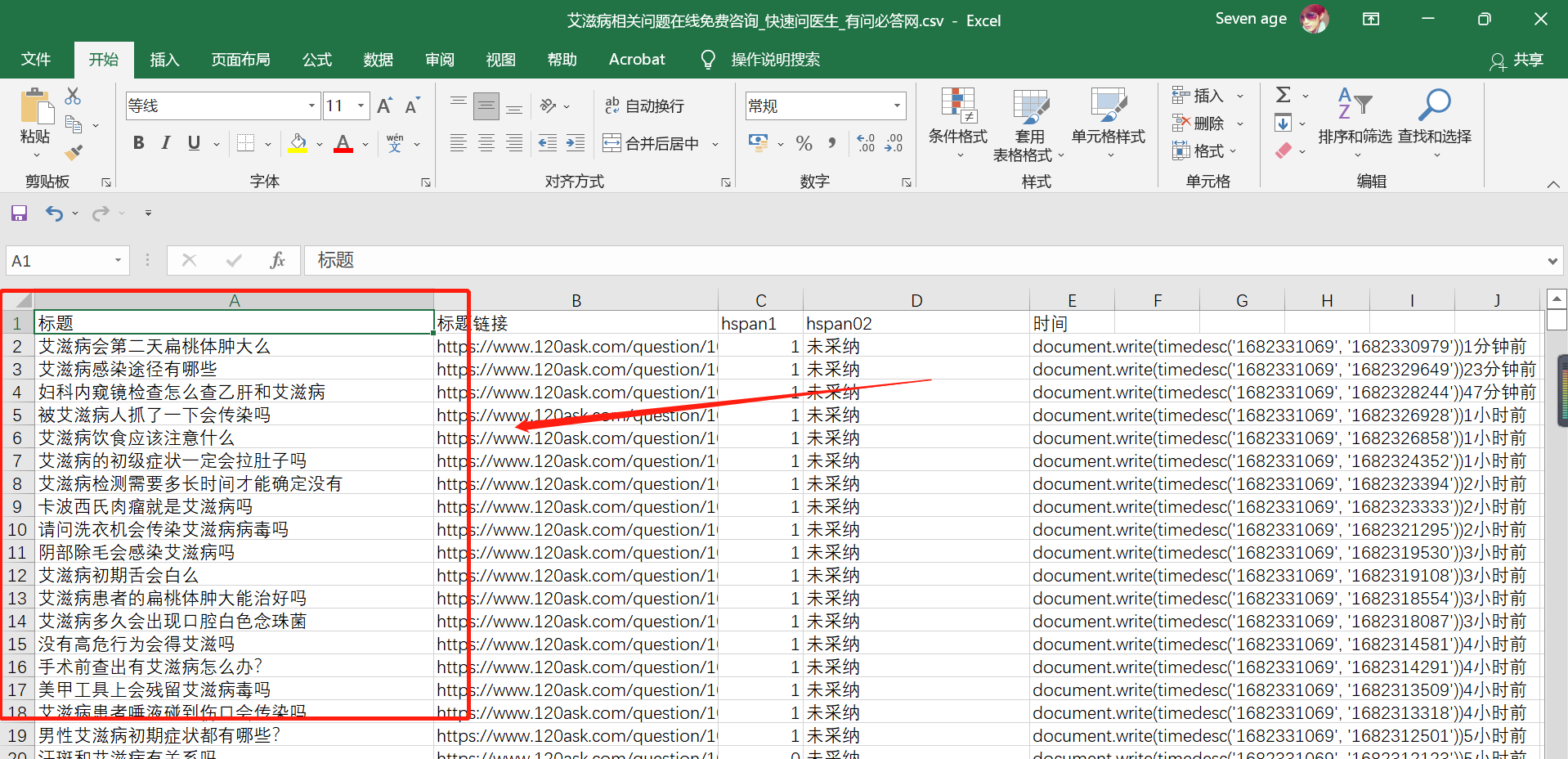
小结
到这里,我们的采集任务就算结束啦,其实操作步骤不难,核心内容为“新建采集”部分,大家先按照我说的要求去做,其他内容先不要设置,否则可能会出错。 需要注意的是:数据采集是一个漫长的过程,这里演示的只是采集一级网页数据,如果多级网页采集时间会更长,有时候会需要采集4-5小时,因此建议初学者不要一次采集过多内容。实际上这个可以通过使用云服务器24h在线采集,由于操作比较麻烦,等后期大家熟练了再教给你们。 好了,到这里简单的数据采集工作就算正式完成啦。我上一期讲过,情感分析应该先于LDA主题模型进行,下一期教大家 如何使用LDA主题模型做情感分析 。情感分析很好玩的,但是可能对评论更有意思一些,对提问效果可能不是特别好,先教大家具体步骤。