
LDA主题模型第二步:文本情感分析
情感分析简介
度过了愉快的五一假期,准备开工,今天主要介绍的是文本情感分析,简单来说,就是对带有情感色彩的主观性文本进行处理、分析、归纳和推理的过程。在互联网上,每天都产生了大量带有情感色彩的文本。例如微博,知乎中关于某一主题的讨论,亦或是淘宝,京东中对商品的评论。这些评论表达了人们的情感色彩和情感倾向。例如:喜、怒、哀、乐、支持、反对、中立等等。情感分析的主要目的是通过分析这些评论来了解某一群体对于某一话题或某一事情的态度和看法。
在护理中的应用
事实上情感分析在护理领域仍处于起步阶段,但有很大的应用空间。
(一)患者对某一疾病的态度
通过分析在线健康信息平台中患者的提问,可以了解患者对该疾病的态度,并比较不同态度患者一般资料差异(也可以比较其他信息,但需要在网络中能提取出);通过分析百度贴吧或天涯社区中帖子的具体内容,来分析患者对某一疾病的情感,是担忧、害怕还是积极乐观;
(二)情绪变化(纵向研究)
通过分析微博树洞中用户发布的内容,了解该用户情绪变化,哪种情绪多一点,进而可以分析他的性格。此外,通过纵向追踪该用户发帖主题的变化,以及帖子的具体内容,凝练提取导致此类性格用户产生某一情绪改变的原因是什么。那么,我们了解这些情感信息可以做什么呢?事实上,现在不同年龄阶段中存在心理健康问题(例如抑郁、焦虑、压力)的人有很多,这些问题不是短时间形成的,往往是在长期的负性事件积累中产生。而许多人不愿意和他人或是父母倾诉,网络的匿名性使得这些人群更愿意通过匿名发帖来吐槽一些事情,或是倾诉某一情感。以青少年为例,如今青少年自杀率逐年升高,抑郁是其自杀的一个重要原因,而在抑郁产生之前,实际上有很多负性事件的积累,例如可能来自家庭的压力过大(家长期望值过高)、遭遇校园暴力和霸凌等等。青少年用户在社交媒体中占了主要部分,当一些情绪或遭遇的时间不愿意和家人或老师诉说时,社交媒体成为这类人群情绪的主要宣泄地。 因此,如果能够提前了解这类用户的情绪变化,构建基于文本情感分析模型的心理健康智能评测系统和心理危机预警系统,将干预提前,可以有效降低这类用户自伤率和自杀率。 情感分析还有很多应用,不止于此,这里只是抛砖引玉。
情感分析前期准备
R语言和Python都可以进行情感分析,但作为机器学习中的方法之一,Python在情感分析方面比R更具优势,因此我们主要使用Python进行。
(一)安装最新版Python和PyCharm
这个安装过程可以看这篇文章,因为知乎上有现成的教程,也很详细,我就不自己出教程了,是用户:星际探险家写的,大家点击链接直达教程,大家一定要记得安装包安装的位置 Python菜鸟入阶第一步(安装Python+PyCharm)
(二)新建项目
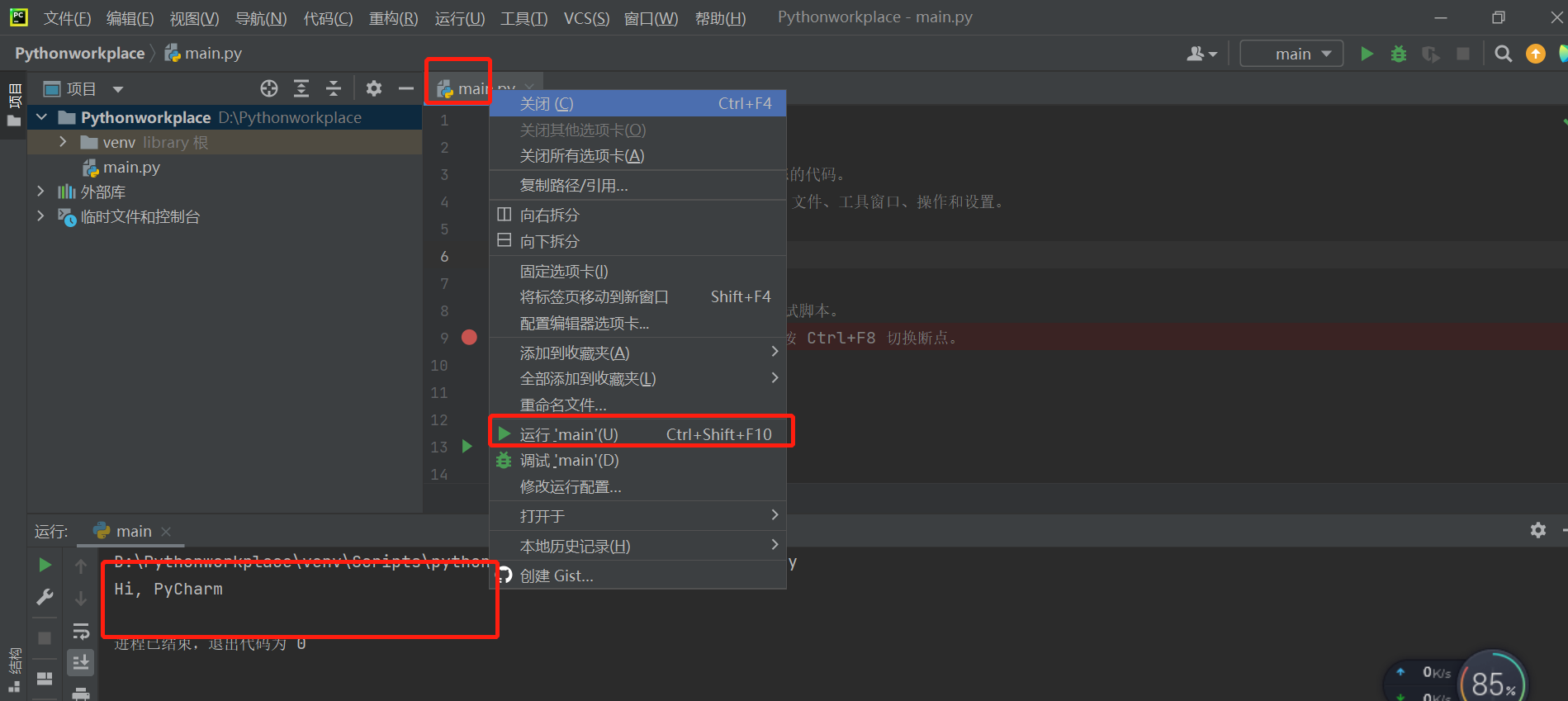
打开pycharm,点击新建项目,项目位置自己设定,记住就行,我是放在D盘了,项目命名为Pythonworkplace。这个命名可以随意,自己能记住就行。如下图,新建后默认会出现一个示例代码,大家点击main.py,右键运行后,下方出现图二中的Hi, PyCharm 表示操作成功。然后大家就可以把这个示例代码删了。直接按Ctrl+A全选,然后删除。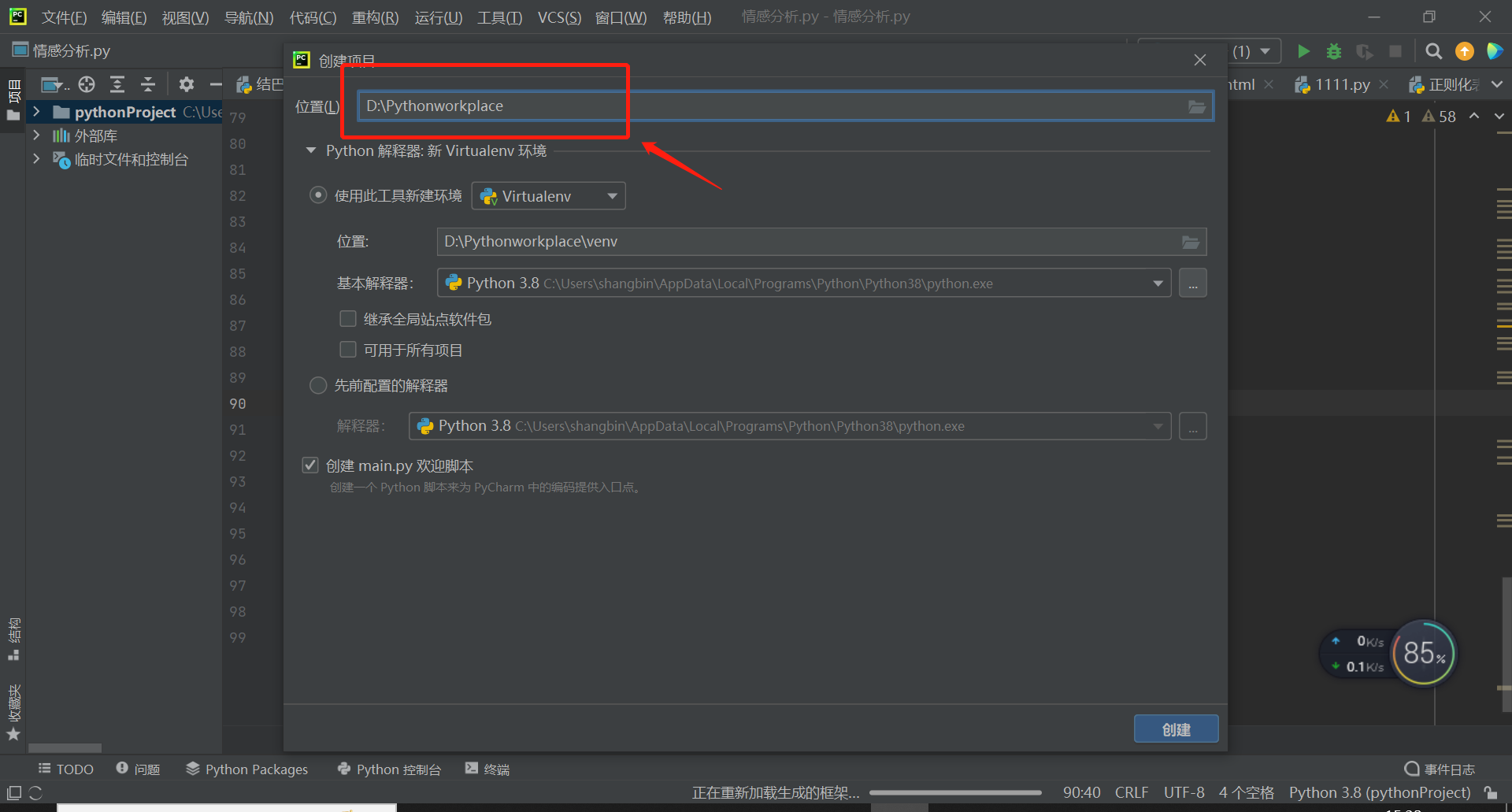
(三)安装软件包
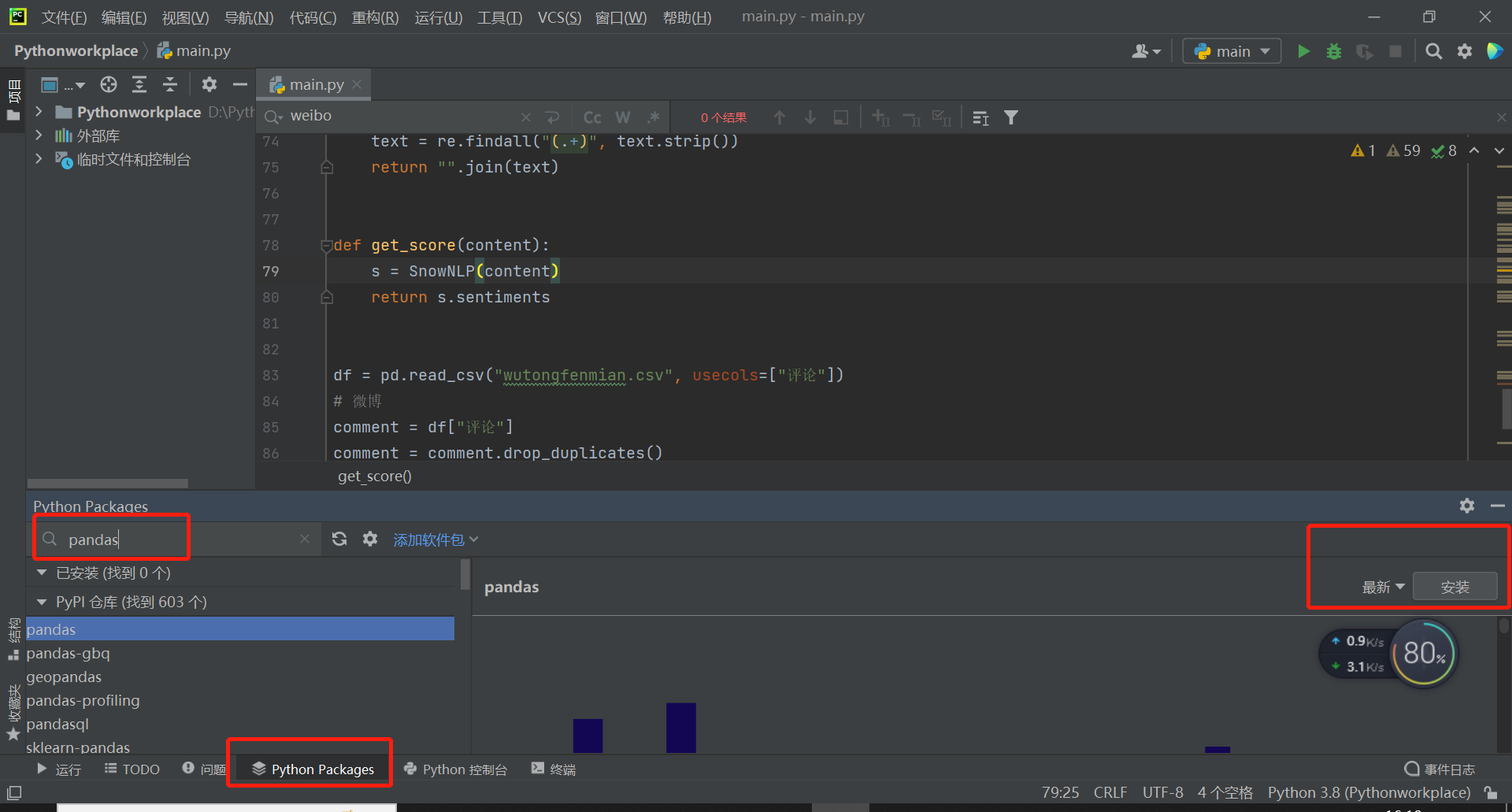
首先请大家安装pandas包,、jieba包、wordcloud包、tqdm包和snownlp包。pandas包主要是用来读取和写入数据的,jieba包用来进行分词,去除停用词,wordcloud包用来绘制词云图,tqdm包主要是显示进度条用的,snownlp包最关键,主要用于情感分析。安装图例如下图,在软件底部点击“python packages”,搜索对应数据包后即可下载,下载稍慢,需要等一会。
(四)准备好一些材料
(1)停用词表和专业词典
停用词表命名为TYC.txt,专业词典命名为YXZD.txt,这两个表可以自己在网上找,停用词表一般常用的是哈工大版本的,专业词典一般找医学的就行。如果不想找的话可以用我的。在百度云,链接点击右侧,提取码1998: 百度网盘资料
(2)文本数据
为了体现衔接性,这里用上一期抓取的HIV数据进行情感分析,我当时抓取了1000多条,差不多够用了,如果没有数据的话可以看上一期教程自行抓取。注意文件格式是CSV格式,文件命名为“Seven.CSV”,注意文件中需要做情感分析那一列的标题改成“评论”两个字。
(3)注意事项
停用词表、专业词典还有文本数据都要放到之间的项目中,我的项目在D盘Pythonworkplace文件夹里,大家如果是自己设定的目录就自己放到对应文件夹里即可。
情感分析代码
大家做好上述步骤后,把下边的代码复制到python中,然后右键运行,就可以在项目文件夹里看到情感分析结果啦。情感分析得分那一列,得分大于0.5为积极或支持态度,得分<0.5为消极或反对态度。也可以划分0-0.4为消极,0.4-0.6为中立或观望态度,大于0.6为积极态度。词云图是词频的可视化,大家基本能看得懂。
#1导入需要的软件包 |
小结
本次主要提到了情感分析的具体操作步骤,实际上代码不怎么难,这次教大家的是最基本的一个版本,事实上情感分析可以分析的情感并不止积极中立和消极。还有很多种形式,例如担心,害怕,开心,冷漠等等。这个涉及到高级一点的情感分析,代码也相对难一些。另外,大家其实做出来会发现,有的情感似乎不太对,或者不符合常理,这里有两个原因,一个是,这次用的是在线社区的提问做的情感分析,实际上,用微博或者抖音评论做出来会更加真实一些,因为评论的色彩更强烈。另外一个是,情感分析属于机器学习,机器学习的前提是有一个前期的训练过程。我们直接调用的这个软件包可能并不符合我们医学或者心理学中的一些情感色彩。最好的做法是先自己手工标注前100例或者更多的情感,再通过语料训练,对模型进行纠正,使模型更加准确,这个也涉及到更高级一些的情感分析,大家刚学习,可以先熟悉流程,等大家熟练后,再教给大家这些高级一些的情感分析,会更加准确。这一期大家的代码可能会有一些报错(如果没按照操作来的话),大家可以先试一试,有错误分享在留言板,谢谢,下一期教大家基于LDA主题模型提取主题。